dram 带宽计算方法以及影响
更新日期:
什么是 dram 带宽
一般提到性能优化,或是硬件性能,大多数人的关注点都在 cpu/gpu 的运算能力,关心到内存指标一般也就是看大小。即便是关注到内存的运行频率,很多人也只是知道越高越好,并不理解内存频率是怎么影响整个系统运行的,可能也没想到过内存带宽可能也会成为整个系统的瓶颈。这篇文章我就来简单的说明一下内存带宽的影响。
dram,也就是 ddr,也就是上面说的内存。它的带宽是指:每秒钟提供的数据访问量,单位我们可以用 Mb/s,或是 Gb/s。系统中任何一个模块访问内存,对内存产生读/写操作,就会生产带宽。例如说播放视频的场景,解码器解码,从片源中解出视频帧存放到内存缓冲里面,这个操作就会产生内存带宽。如果某个时刻系统所有模块产生的带宽超过了内存提供的带宽访问量,那么就会产生性能问题。
分析某个应用场景是否存在带宽问题,只要能罗列出该场景主要模块的内存访问情况,就可以计算出来是否超过了系统内存最大带宽。所以需要对目标场景的数据流动很熟悉,才能做带宽分析。
总带宽计算公式
|
|
1 . dram 运行频率:
这个由 soc 的 ddr 控制模块决定能支持的最高 ddr 运行频率。例如说现在手机上的高通骁龙820,支持最高的 LPDDR4 是 1333MHz。而我开发过的 VR 平台已经是本公司目前为止运行频率最高的了,也就 976MHz。当然实际运行频率还和最终产品选的 ddr 物料有关系,我们这里假设都以最高频率算。
2. 位宽:
|
|
一般 ddr 都是上下沿采样数据的,这相当于一次采用都有双倍数据,上升沿一次,下降沿一次(ddr 的全称叫:Double Data Rate SDRAM,双倍数据流 SDRAM)。
一次采样数据的带宽呢,这个就要去问系统设计 ddr 模块的了。例如说从高通官网可以查看 820 的 Memory 带宽是 4通道16bit 的,所以 820 的位宽是 4x16 = 64bit(8Byte),再乘以上下沿双倍 = 16Byte。
而我开发过的 VR 平台采用的是本公司高端一点的 ddr 规格,单通道 32bit(低端的就是 16bit 了),最终 位宽 = 32 x 2= 32bit(8Byte)。
3. 效率:
dram 的理论带宽上面已经可以计算得出来了,例如说拿我举例的 高通820 和 我开发过的 VR 平台:
|
|
但是实际上存在一个实际利用率,得打个折扣。至于这个折扣是多少,一般 soc 厂家不会公开(这个可能涉及到 IP 设计了),一般业界保守都按 70% 算。例如说上面 820 的,打个 7折 后,实际估算带宽是 14.7GB/s。
我开发过的 VR 平台,ddr 同事提醒总带宽不要超过 4GB/s ,按这个推算效率大概为 50%。至于为什么,反正也说不清楚,比较玄学,可能是整体系统总线之类的差人家高通一截吧。
模块计算案例
上面说了整个 dram 的带宽计算公式。现在以一个简单的场景来说明一下模块的带宽是怎么计算的。例如说我们在 Launcher 界面静止不动情况:
Launcher 静止界面: HWC 合成
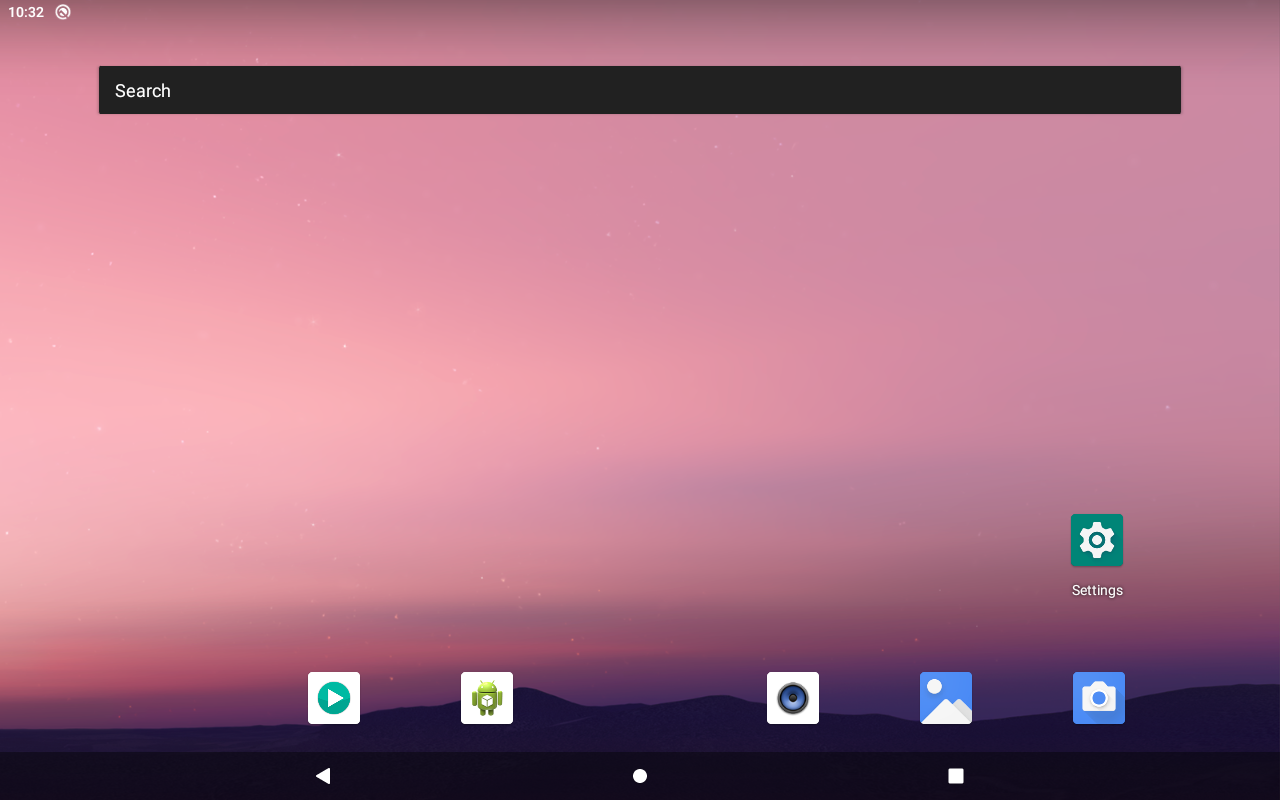
这个时候用统计带宽的工具看一下各个模块的带宽数值(一般这个工具 soc 厂家都会有,应该都是访问内部节点得到的):

简单解释一下这个工具的含义(下面单位都是 MB/s):
- totddr 是总带宽:685MB/s
- cpudrr 是 cpu 的带宽:53MB/s
- gpuddr 是 gpu 的带宽:是 0
- de_ddr 是 显示模块(hwc 和 一些硬件图像处理等) 的带宽:632MB/s
- ve_ddr 是 解码器 的:是 0
- csi_ddr 先不管吧
场景是 Launcher 静止界面,我们来分析一下为什么 de 模块(显示模块)会有 632MB/s 的带宽。我们这边把 显示模块,叫 de(display engine),它里面包含了 android 常见的 hwc 功能,还有我们这边特有的一些硬件图像处理功能,例如说 护眼模式(去蓝光),G2D(图像旋转功能)。
dumpsys SurfaceFlinger 看一下图层信息:
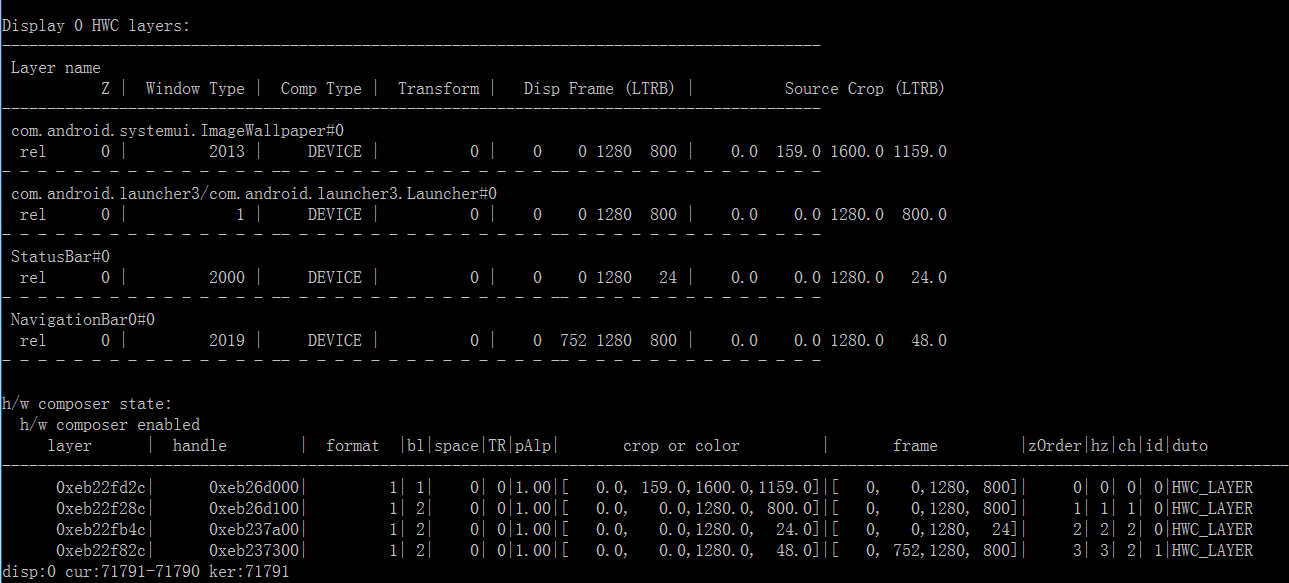
可以看目前的场景有4个图层:
- ImageWallpaper:壁纸
- Launcher3:桌面应用
- StatusBar:状态兰
- NavigationBar:导航栏
这4个图层都是 hwc 合成方式(Comp Type:DEVICE 代表的就是 hwc 合成)。hwc 合成就是我们说的硬件合成方式,也就是图层直接发下给 hwc,不需要 gpu 处理。hwc 会读取每一个图层的 Buffer 数据,然后送给 LCD 显示。这里我们就能发现了:hwc 存在 dram 访问操作,hwc 合成的时候需要去读取每一个图层的数据。所以就会产生上面的 de 带宽。
我们来计算一下 632MB/s 是怎么来的。我们看一下目前 LCD 控制器的刷新率(这个每个平台都不太一样,我这里是我们平台提供的节点看到的,当然了一般刷新率可以取 60Hz):

是 61Hz。也就是说 hwc 每秒要给 LCD 送 61 次图像。虽然图像没有更新,但是 LCD 每秒都是在刷新的。所以这个场景下 de 的带宽计算方法就是:所有图层的数据大小 x 61。
图层的数据大小为:图层的长 x 高 x 单个像素的字节
注意:长 x 高 要选 Source Crop 那里的大小,这个才是图层原始的大小,前面那个 Disp Frame 是显示的大小。也就是说图层有可能经过缩放(典型的就是 壁纸 和 视频播放)。单个像素占用的字节和图层的颜色格式有关系。图层格式,dumpsys SurfaceFlinger 里面可以看得到。对应关系在:android/system/core/include/system/graphics.h 里面:
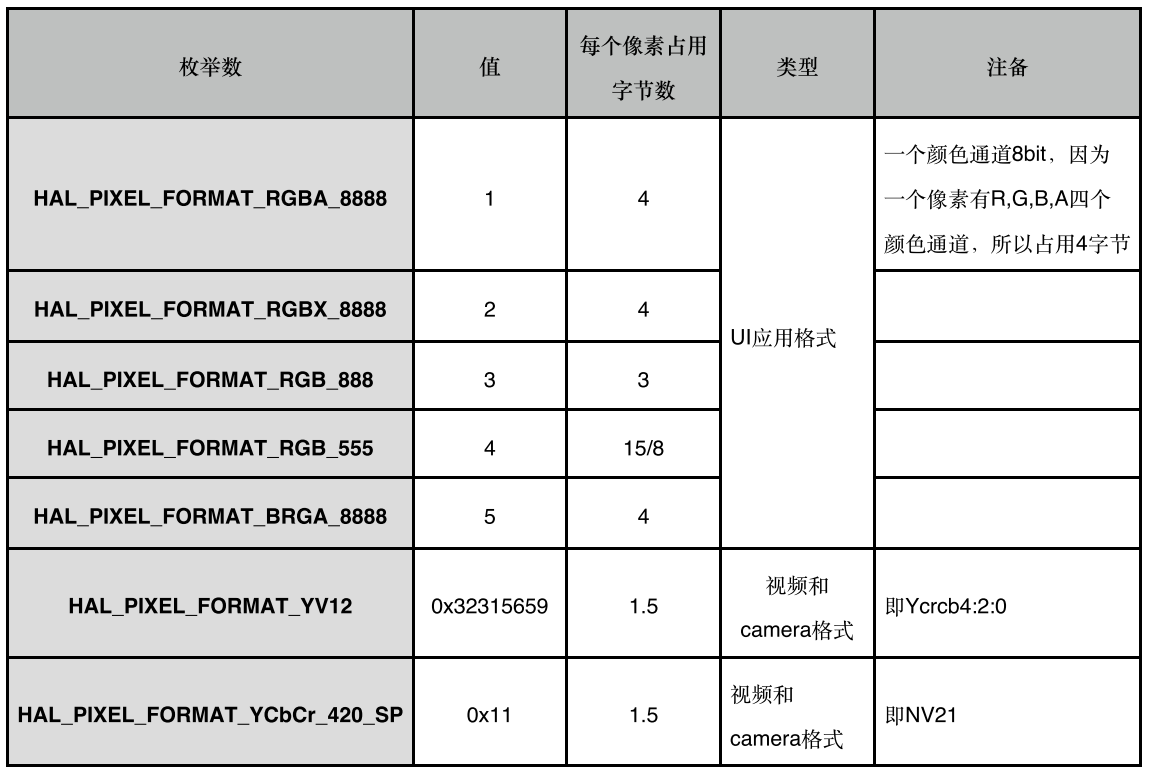
我们现在就可以计算 de 占用的带宽了:
|
|
结合我之前内存分析的文章:Android 内存优化方法#malloc_debug,我们发现原生壁纸这玩意又费内存,又费带宽,没什么必要的话,可以考虑去掉。我们试着把合成方式改成 GPU 合成:
Launcher 静止界面: GPU 合成
在 Settings 里面打开 开发者选项,把 强制GPU合成 的开关打开,然后这个时候再回到 Launcher 静止界面,我们用带宽工具看一下:

会发现 de 的带宽低了很多。这个是怎么回事呢,我们再来分析一下,首选 dumpsys SurfaceFlinger:
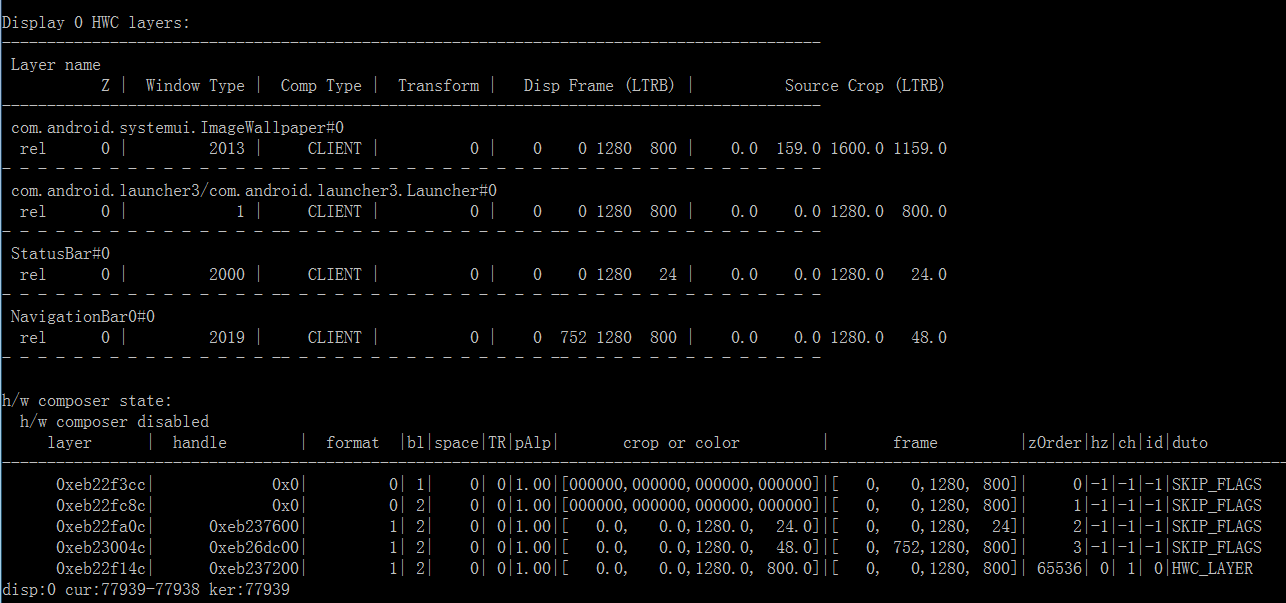
这个时候看到图层的合成方式已经变成了 CLIENT 了,这个就代表是 gpu 合成。gpu 合成 SurfaceFlinger 会遍历所有图层,然后把每一个图层用 OpenGL 贴到一个 FrameBuffer Surface 的图层上,然后再把 FrameBuffer Surface 送给 hwc 送显。从上面的数据流向,应该是觉得会有 gpu 带宽的(因为 openGL 贴图相当于是读写了图层的 Buffer 内容),但是需要注意的是:这是静止时候的场景,在没有图像更新的时候,不需要合成图像的;只需要 hwc 给 LCD 送显就行了。由于 SurfaceFlinger 已经把图层合并到 FrameBuffer Surface 这一个图层送下来了,所以此时的 hwc 相当于是只有一个 1280x800(屏幕大小) 的图层需要处理(这里注意看送给 hwc 的 layer 只剩下一个了,就是 h/w composer state 那里标着 HWC LAYER 的,这个就是前面说的 FrameBuffer Surface)。所以这时候 de 的带宽是:
|
|
这个时候大家就发现了,在没有图像更新的场景,使用 gpu 合成反而 hwc 的带宽更低,同时也能降低功耗,所以这其实是一个优化点。但是有图像更新的场景,hwc 合成就能表现出它的优势了:
60fps 视频播放场景: HWC 合成
例如说我们拿一个播放 1080p@60fps 视频的场景来分析一下。拿 AOSP 的 gallery 播放一个 1080p@60fps 的片源:

先看一下带宽:

现在可以看到 cpu 和 ve 有带宽了,现在我们不分析这2个,因为解码器的内部流程我不是很熟,所以如果要分析,需要解码器的同事的协助。我们看到现在 de 带宽是 419 MB/s,gpu 是 0。我们 dumpsys SurfaceFlinger 看一下图层:
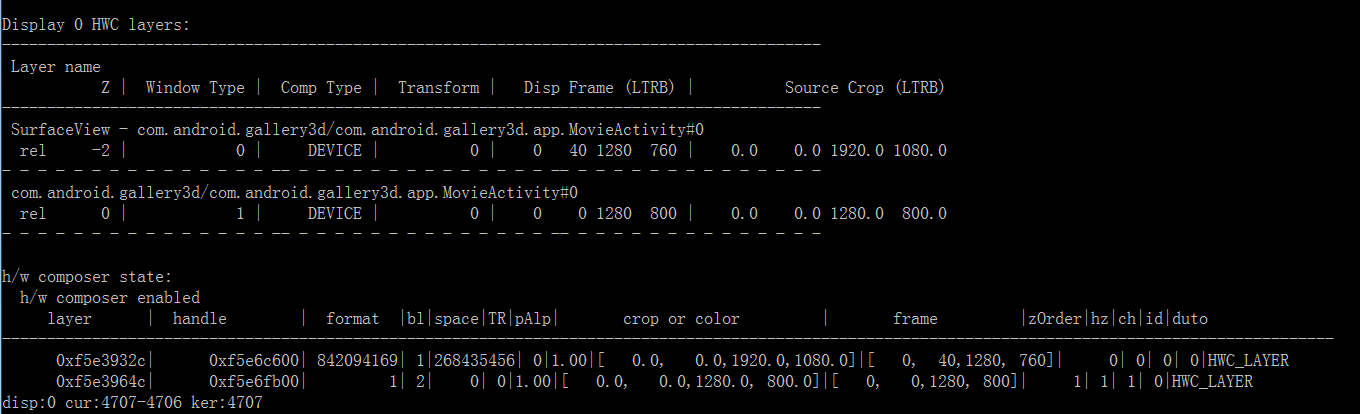
只有2个图层了:
- SurfaecView:视频图像输出图层(
- VideoPlayerActivity:播放界面的图层
目前这2个图层是用 HWC 合成方式的,所以按上面的计算方式:
|
|
我们换成 gpu 合成:
60fps 视频播放场景: GPU 合成
看一下带宽:

然后再 dumpsys SurfaceFlinger 看一下图层:
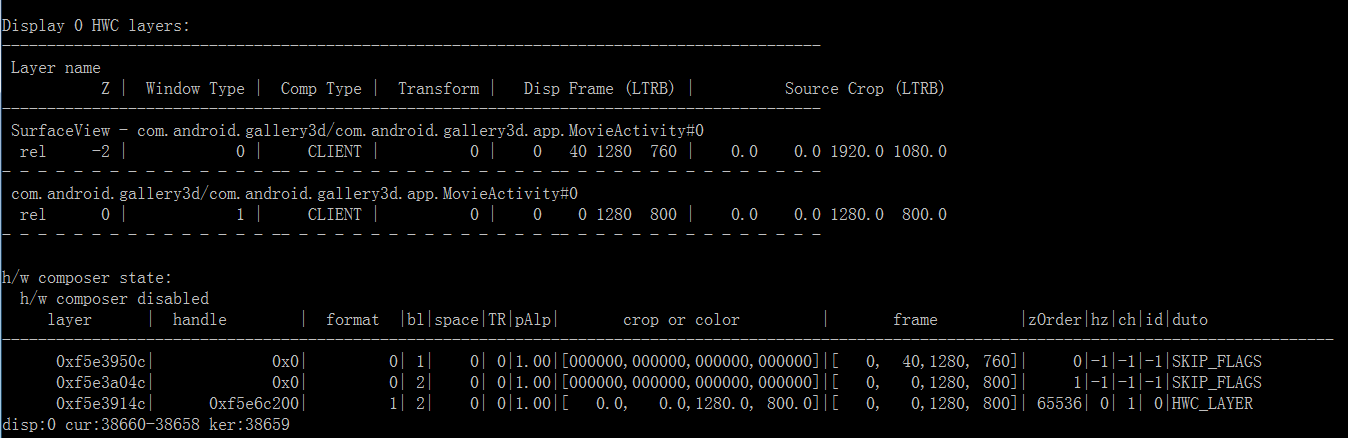
同样是2个图层,gpu 合成,目前 de 的带宽 239MB/s 和前面 Launcher 静止的场景是一样的。然后再来计算下 gpu 的带宽,因为有图像更新了,所以 SurfaceFlinger 需要对每个图层的 Buffer 数据进行一次读操作,然后再贴到 FrameBuffer Surface,也就是要把这些 Buffer 再写到另外一个 Buffer 里面,所以一个图层需要一次读和写内存访问,图层数据得 x 2。前面看到 LCD 的刷新率是 61,但是这里我们其实得看应用的帧率,我们通过抓 systrace,截取 1s 统计 SurfaceFlinger 合成 Layer 的次数(doComposition 的次数),看到 1s 是 60fps:
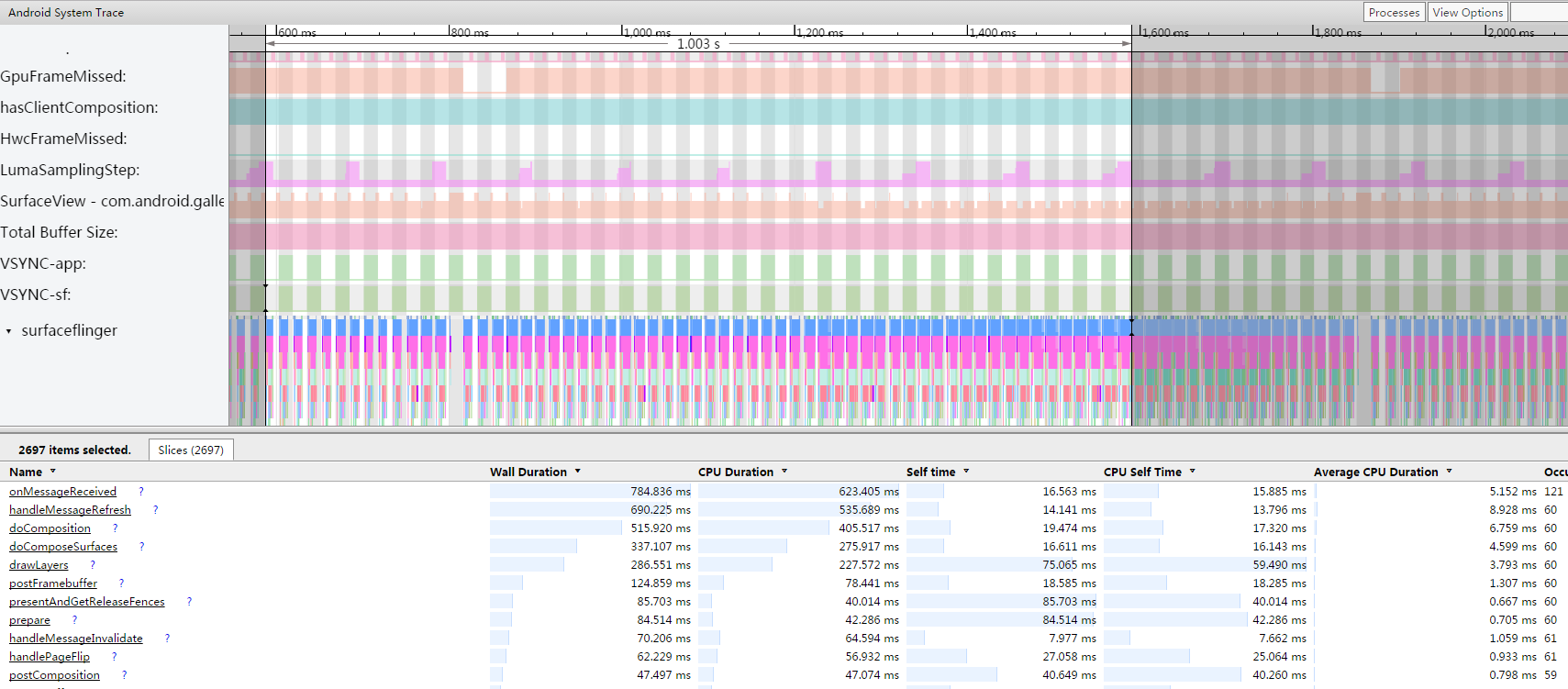
所以 gpu 带宽的计算为:
|
|
gpu 这边理论的计算和实测有点点差距,不过大体还是接近的。
总结
对比图像有更新的场景能看到,hwc 合成的总带宽为 2.2GB/s,gpu 合成的总带宽为 3GB/s。hwc 合成的优势就体现出来了,这也就是 google 为什么要在 android 上设计这个硬件模块的目的。并且 gpu 合成还需要额外占用 gpu 负载(gpu 工作了)。所以大多数情况下 hwc 合成在 性能 和 功耗上都更具优势(前面说的画面静止场景除外)。
那什么时候会出现带宽瓶颈呢。例如说:我们公司的某些平台,解码器是支持 4k@30fps(3840x2160@30fps) 解码的。显示用 hwc 合成,gpu 也没负载,cpu 也能扛得动(硬解 cpu 占用率不高的),但是其实这个时候系统是没法给用户以 30fps 的速度播放视频的。因为前面看到 1280x800 的分辨率 hwc 合成下播放 1080p@60fps 的视频都已经是 2.2GB/s 的带宽了,如果同样还是这个平台,此时视频图层的数据量就为 1080p@60fps 的2倍(3840x2160x30 vs 1920x1080x60)。我们来估算一下这个场景下的总带宽:
|
|
4.4GB/s,我们的平台基本上抗不住了。这个时候就会出现几个模块争抢带宽的情况。简单的说,如果哪个模块优先级低了,没抢到带宽,那么它就处理不了原来那么多的数据了:
- 如果是 de 模块带宽被抢了,造成的后果往往是花屏。所以 de 一般优先级得最高
- 如果是 ve 模块带宽被抢了,造成的后果就是解码丢帧。用户看到的情况就是视频播放变卡了。
所以有些时候我们看到界面卡了,可能瓶颈并不在 cpu、gpu 和 内存占用,可能是带宽不够了。